DeepSeek's Rise: From Code to Conversation
DeepSeek may not have been in the public eye much until the last week or so, but its research has been on the radar for some time. Their first releases back in 2023, called DeepSeek-Coder, was a series of open-source code generation models made for supporting developers and at the time was deemed the best performing model at this task available.
The Chinese government has placed great emphasis on AI development, encouraging Chinese tech companies to take on the US technology giants. In response, the US government has banned the export of high-end chips to China since 2022 in order to make it harder for Chinese companies to compete.
Not only has the release of the larger R1 model had an impact on the AI landscape, DeepSeek also released a series of 6 smaller, distilled models based on two previous open-source models from Meta and Alibaba (Llama3 and Qwen2.5). Deepseek finetuned the models using their R1 model in a teacher-student method, producing powerful “reasoning” models that can be run on consumer grade technology. This enables more efficient and accessible AI, giving users the ability to run and develop these incredibly powerful models further on consumer technology. That in turn will allow users to utilise these models within their working processes, with the user or the model not needing to touch the internet once the model is downloaded, keeping all your chats, data and work safe within your local environment.
Performance vs. Hype: Digging Deeper into the Benchmarks
It’s true to say that in terms of capability, R1 is an attempt to rival the ability of the latest OpenAI models and the fact that based on the benchmarks it gets close is an achievement in itself. There is scepticism around the AI community whether its real performance in the hands of users reflects that of its benchmark results. More recent trials performed by users and researchers out in the open world have shown that the real performance is far from that of OpenAI’s o1 and actually much closer to OpenAi’s o1-mini, with prompt sensitivity being one of the main areas of concern. Prompt sensitivity is where tweaks to instructions, essentially saying or meaning the same in pure English, give massively variable outcomes. When it comes to the benchmarks themselves, there have been studies into whether large language models, can genuinely reason or primary depend on token bias (the bias learned towards the use of specific tokens). This measure discussed in by Bowen Jiang et al states:
“A strong token bias suggests that the model is relying on superficial patterns in the input rather than truly understanding the underlying reasoning task.” [1]
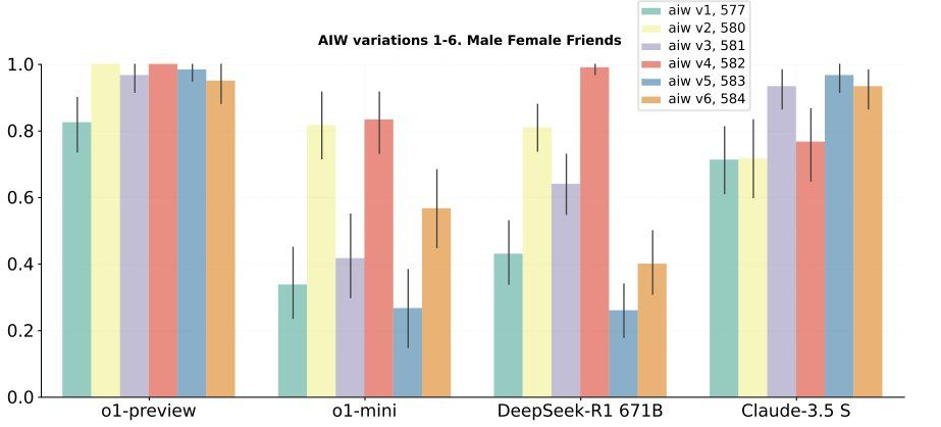
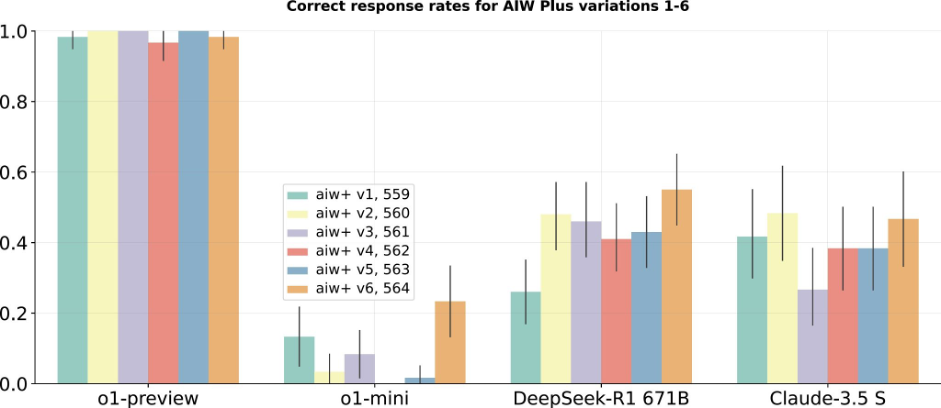
This suggests that using variations of the words from the original benchmark questions significantly changes the quality of their response. This heavily suggests that the questions themselves have been included in the training data and rather than reasoning to the answer, the model has memorised the answer from its training. Ignacio de Gergorio Noblejas, a prominent voice in the AI community has recently taken to LinkedIn discussing whether the benchmarks are a good indication into a model’s “smartness.” [2] He suggests that the current benchmarks may be misleading, focusing more on surface-level accuracy rather than deeper cognitive capabilities. He then goes on to reference work by Jenia Jitsev (unverifiable) who has tested R1 and other models using the Alice in Wonderland (AIW) methodology [3], scoring how language models perform on seemingly simple tasks that are easy for a human. This shows R1 is extremely sensitive to token bias and performs closer to the level of OpenAI’s o1-mini when variations are introduced to the questions for the benchmark (Fig 1.) and more akin to Anthropic’s Claude 3.5 Sonnet when the complexity of the variations is increased further (Fig 2.).